尝试实现GPT
这是根据大佬Andrej Karpathy
https://www.youtube.com/watch?v=kCc8FmEb1nY
代码仓库:
https://github.com/karpathy/ng-video-lecture
做的实现和笔记。该视频分为几个部分:一是讲述GPT的基本原理;二是根据GPT基本原理,从头实现一个简单的GPT——可以学习莎士比亚的写作风格,对已有的戏剧文本进行续写
最简单的神经网络
在最开始的部分,Andrej首先带领我们构造一个最基本的网络,使得大家对文本生成模型有一个基本的认识和理解。(有助于神经网络小白大致了解神经网络的工作过程)。可以看到这个流程分为几个部分:
定义了最简单的encoder,用于把文本转换为数字类型,进而转换为张量,便于神经网络进行学习。decoder则是用于把神经网络的输出转换为数字
定义简单的BigramLanguageModel,它的两个核心函数:
forward函数(定义了数据在神经网络中各个层的传播方式)可以看到这里的实现很简单:通过词嵌入层将输入的词汇索引转换为对应的嵌入向量。这些向量作为模型的输出,并将这个向量作为下一个词的概率分布的直接预测。(具体咋预测,看下面的生成函数)
generate函数,传入的idx参数(是个 (B,T) array of indices in the current context),代表一系列词汇的起始序列;max_new_tokens表示要生成的最大新词的长度。可以看到generate是如何进行“预测”的:首先通过self(idx)自动调用forward方法,得到一个logit;然后,focus only on the last time step,只选择对于当前序列中最后一个词的预测输出logits = logits[:, -1, :] ;之后使用softmax得到概率 probs = F.softmax(logits, dim=1) ,输出的形状是(B, T+1) ,每行就是一个词对应的概率分布;最后,idx_next = torch.multinomial(probs, num_samples=1) ,从每个概率分布中采样一个样本(就是一个词的索引),然后把新的索引加到idx序列中。
# 一个简单的,没有经过严谨训练的模型
import torch
import torch.nn as nn
from torch.nn import functional as F
#####################PreDefine###############################
device = 'cuda' if torch.cuda.is_available() else 'cpu'
with open('input.txt', 'r',encoding='utf-8') as f:
text = f.read()
chars = sorted(list(set(text)))
vocab_size = len(chars)
# 创建字符到整数的映射 有许多第三方库可以完成这个任务,现在我们只是使用最简单的方法
stoi = {ch:i for i,ch in enumerate(chars)}
# enumerate函数返回一个元组,第一个元素是索引,第二个元素是值。
itos = {i:ch for i,ch in enumerate(chars)}
encoder = lambda s: [stoi[c] for c in s]
decoder = lambda l: ''.join([itos[i] for i in l])
data = torch.tensor(encoder(text), dtype = torch.long) # 将这个列表转换成一个 PyTorch 张量,用于训练模型
batch_size = 4 #
block_size = 8 # 训练“预测”能力时候的最大长度
n = int(0.9 * len(data))
train_data = data[:n]
val_data = data[n:]
def get_batch(split):
#生成输入x和目标y
data = train_data if split == 'train' else val_data
ix = torch.randint(len(data) - block_size, (batch_size, )) # 随即抓取一块
x = torch.stack([data[i: i+block_size] for i in ix])
y = torch.stack([data[i+1: i+block_size+1] for i in ix])
x, y = x.to(device), y.to(device)
return x,y
xb, yb = get_batch('train')
###################PreDefine###################
class BigramLanguageModel(nn.Module):
def __init__(self, vocab_size) -> None:
super().__init__()
self.token_embedding_table = nn.Embedding(vocab_size, vocab_size) #一个随机的浮点权重矩阵
def forward(self, idx, targets=None):
logits = self.token_embedding_table(idx) # [B, T, C] 旧版
if targets is None:
loss = None
else:
B, T, C = logits.shape
logits = logits.view(B*T, C) # 维度重塑,便于满足交叉熵的计算要求
targets = targets.view(B*T)
# 评估预测的质量 Compute the cross entropy loss between input logits and target.
loss = F.cross_entropy(logits, targets)
return logits, loss
def generate(self, idx, max_new_tokens):
for _ in range(max_new_tokens): # 循环生成新词
# get predictions
logits, loss = self(idx) # 内部调用forward方法
logits = logits[:, -1, :] # (B,C)
# 使用softmax得到概率
probs = F.softmax(logits, dim=1) # (B, T+1) 每行就是一个词对应的概率分布
# sample from the distribution
idx_next = torch.multinomial(probs, num_samples=1)
# append the sampled index to the sequence
idx = torch.cat((idx, idx_next), dim=1) #(B, T+1)
print("idx22222----------------", idx)
return idx
m = BigramLanguageModel(vocab_size)
m = m.to(device)
logits, loss = m(xb, yb)
print(logits.shape)
print("loss-----------------", loss)
# 以上的步骤构建出来的模型是随机的,所以输出是垃圾;我们要对模型进行训练
#create a pytorch optimizer
optimizer = torch.optim.AdamW(m.parameters(), lr = 1e-3)
# 一般学习率是3e-4,但是我们的网络小,可以设置高一些
batch_size = 32
for steps in range(4):
# sample a batch of data
xb, yb = get_batch('train')
logits, loss = m(xb, yb)
optimizer.zero_grad(set_to_none=True)
loss.backward()
optimizer.step()
print(loss.item())
context = torch.zeros((1, 1), dtype=torch.long, device=device)
# print(m.generate(idx = torch.zeros((1,1), dtype = torch.long), max_new_tokens = 10))
print(decoder(m.generate(idx=torch.zeros((1,1), dtype=torch.long), max_new_tokens=1000)[0].tolist()))使用Transformer
加入注意力机制
所谓注意力,就是关注过去的序列,不关注未来的.
首先,我们使用一个权重矩阵的例子,并看看它从版本0到升级2的实现;希望从而说明self-attention中的重要思想。
原版0:
torch.manual_seed(1337)
B,T,C = 4, 8 ,32
x = torch.randn(B, T, C)
# below: single head perform self-attention
head_size = 16
tril = torch.tril(torch.ones(T, T))
wei = torch.zeros((T, T))
wei = wei.masked_fill(tril == 0, float('-inf'))
wei = F.softmax(wei, dim = -1)
out = wei @ x升级1:
torch.manual_seed(1337)
B,T,C = 4, 8 ,32
x = torch.randn(B, T, C)
# below: single head perform self-attention
head_size = 16
key = nn.Linear(C, head_size, bias = False) #
query = nn.Linear(C, head_size, bias = False)
k = key(x)
q = query(x)
wei = q @ k.transpose(-2, -1)
print(wei)
tril = torch.tril(torch.ones(T, T))
wei = wei.masked_fill(tril == 0, float('-inf'))
wei = F.softmax(wei, dim = -1)
out = wei @ x升级2:
torch.manual_seed(1337)
B,T,C = 4, 8 ,32
x = torch.randn(B, T, C)
# below: single head perform self-attention
head_size = 16
key = nn.Linear(C, head_size, bias = False) #
query = nn.Linear(C, head_size, bias = False)
value = nn.Linear(C, head_size, bias = False)
k = key(x)
q = query(x)
wei = q @ k.transpose(-2, -1)
print(wei)
tril = torch.tril(torch.ones(T, T))
wei = wei.masked_fill(tril == 0, float('-inf'))
wei = F.softmax(wei, dim = -1)
v = value(x)
out = wei @ vimport torch x = torch.randn(B, T, C) # 通过标准正态分布随机生成 key = nn.Linear(C, head_size, bias = False) # 对输入数据进行线性变换,特征维度从 C 映射到 head_size wei = q @ k.transpose(-2, -1) # 结合点积的几何意义: 每个点积分数表示对应键(即输入位置)与当前查询的匹配程度。
原版0:
这时候如果我们把wei输出来,它会是一个0,1矩阵(上三角是0,下三角是1,是uniform的);
这样的wei是不好的,显然它无法体现谁更加重要,无法帮助token捕捉互相之间的关系,从而帮助一个token找到它可能感兴趣的另一个token(比如,在我们文本预测的场景下,一个辅音字母后面大概率跟着元音字母,所以它的token会对元音字母的token更加感兴趣)
升级1:
于是我们看到,对于token x,我们还会计算它的query和key。一般来说,query表示token x想要什么;key表示x含有什么。那么想象一下,这时候如果我们有一个token A和token B,那么把query A和key B做点积,就可以知道B是否是A感兴趣的。(记得点积的几何意义吗?他表示两个向量各个维度的相似程度!如果query A和key B相似程度很高,那么我们可以认为B对A是感兴趣的)
之后我们的wei输出来就是这样的:

升级2:
像生成query和key的方法一样,为x生成了value,这个value可以视作x的被进一步提取出来的信息,用于告诉其它token:嘿,如果我的key表明我是你在找的人,那么这些,在value里面,是我要告诉你的!
总结:
正如我们刚刚看到的,所谓注意力机制,其实是“沟通机制”,它使得token之间不是孤立的,而是会发生交流,找到更加适合自己的“那些人”。
“注意力”是没有空间的概念的(很多时候,我们用到向量,和向量联系的概念之一就是空间对吧,但是在这里,没有空间的概念,这也是为什么,我们还会为Transformer加入空间编码。)(这和其它一些框架,比如CNN,是不一样的)
在本篇教程的学习案例里面,我们使用下三角矩阵屏蔽了未来的特征,但其实这不是必要的。我们是在实现一个decoder模块;如果是要实现一个encoder模块,那么我们就不想要屏蔽未来的特征值了。
自注意力和交叉注意力。我们这里是自注意力机制。相信你也发现了,在“升级”代码中,query和key是来源于同一个x,而不是分别来源于x和y。交叉注意机制就是不同的token之间进行交流。(自交流也没有什么问题,自己也可以从自己身上学到东西嘛,一个token的不同维度不同数值也可以互相交流)
实现单头注意力机制的代码如下;多头注意力的实现也很简单:
class Head(nn.Module):
def __init__(self, head_size):
super().__init__()
self.key = nn.Linear(n_embed, head_size, bias = False) # 对输入数据进行线性变换,特征维度从 C 映射到 head_size
self.query = nn.Linear(n_embed, head_size, bias = False)
self.value = nn.Linear(n_embed, head_size, bias = False)
self.register_buffer('tril', torch.tril(torch.ones(block_size, block_size)))
self.dropout = nn.Dropout(dropout)
def forward(self, x):
B,T,C = x.shape
k = self.key(x)
q = self.key(x)
# compute attention scores(亲和性,相似度)
wei = q @ k.transpose(-2, -1) * k.shape[-1]**-0.5
wei = wei.masked_fill(self.tril[:T, :T]==0, float('-inf'))
wei = F.softmax(wei, dim = -1)
wei = self.dropout(wei)
# perform the weighted aggregation
v = self.value(x)
out = wei @ v
return out
class MultiHeadAttention(nn.Module):
def __init__(self, num_heads, head_size):
super.__init__()
self.heads = nn.ModuleList([Head(head_size) for _ in range(num_heads)])
self.proj = nn.Linear(head_size * num_heads, n_embd)
self.dropout = nn.Dropout(dropout)
def forward(self, x):
out = torc.cat([h(x) for h in self.heads], dim = -1)
out = self.dropout(self.proj(out))
return outFeedForward_多层感知机
想象一下,通过刚刚引入的注意力机制,我们的某个token拿到了他感兴趣的“那个人”的信息,那么接下来,他是不是要处理这些信息呢?
也就是先communication,再computation;
我们构造一个简单的前向传播层来做这个事情。
class FeedForward(nn.Module):
def __init__(self, n_embd):
super().__init__()
self.net = nn.Sequential(
nn.Linear(n_embd, 4 * n_embd),
nn.ReLu(),
nn.Linear(4 * n_embd, n_embd),
nn.Dropout(dropout)
)
def forward(self, x):
self.net(x)使用Block来封装先communication,再computation的操作,这个Block类,我们后面说完LayerNorm再解释。
一些问题
我们引入位置编码,注意力机制,前向传播之后进行训练,会发现效果依然不好,原因是,我们的神经网络加深了,随之而来了一些问题,比如使得神经网络不能持续优化。
有两种解决办法:
残差连接 Residual
残差连接,这个在我们已经给出的代码里已经体现了一部分。如图所示,Residual Connection(残差连接)是一种在深度学习模型中常用的技术,特别是在深度神经网络中。它通过将网络中某一层的输入直接添加到该层的输出上,来帮助缓解梯度消失的问题,并且可以提高模型的训练效率和准确性。
在
MultiHeadAttention类的forward方法中,每个头(h)处理输入x后,所有头的输出被拼接起来,然后通过一个全连接层和dropout层。
Layer Norm
进行完成上面的介绍后,我们把几个组件封装到一起,形成Transformer中基本的Block功能模块。
class Block(nn.Modle):
def __init__(self, n_embd, n_head):
super().__init__()
head_size = n_embd
self.sa = MultiHeadAttention(n_head, head_size)
self.ffwd = FeedForward(n_embd)
self.ln1 = nn.LayerNorm(n_embd)
self.ln2 = nn.LayerNorm(n_embd)
def forward(self, x):
#自注意力机制处理 归一化,残差连接
x = x + self.sa(self.ln1(x))
#前馈网络处理 归一化,残差连接
x = x + self.ffwd(self.ln2(x))
return xGPT诞生
在这个教程对应的任务里,只需要decoder,而一些任务,则需要动用完整的TF框架,比如一个把法语翻译为英语的任务。
所以我们的TF是一个没有encoder的框架,也没有encoder和decoder之间的一些交互作用。和GPT一样,我们的model是一个decoder-only-transformer。(其实关于GPT为啥是decoder-only的,有更深层次的原因,争取之后学习并整理成博客)
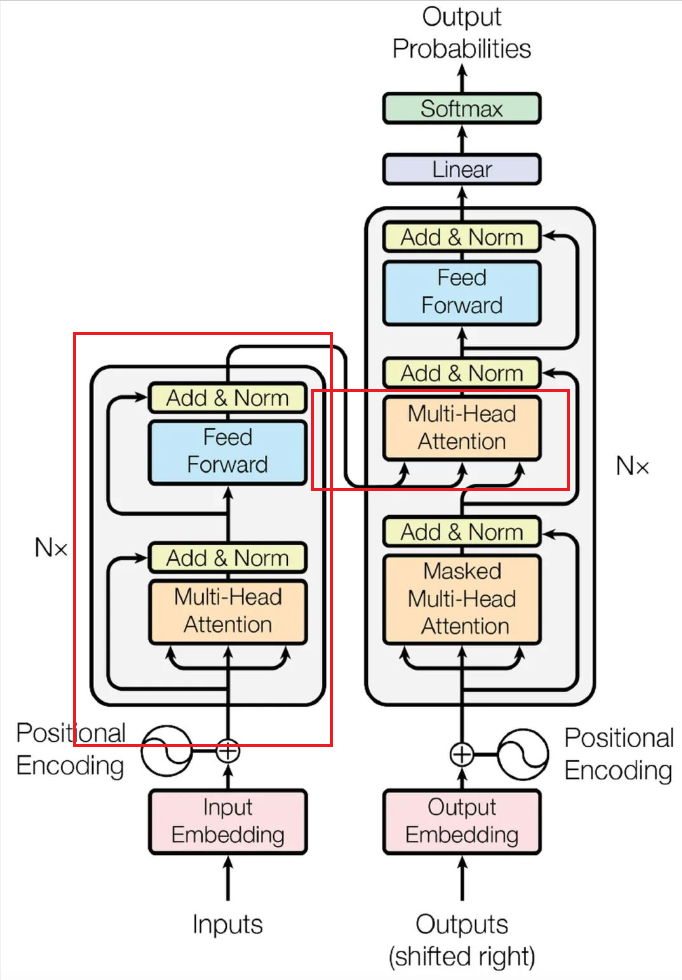
综合上面我们实现的一些组件,最后的GPT长这样:
注:
self.apply(self._init_weights)用于遍历GPTLanguageModel实例中的所有子模块,并调用_init_weights函数对这些子模块的权重进行初始化
class GPTLanguageModel(nn.Modle):
def __init__(self):
super().__init__()
self.token_embedding_table = nn.Embedding(vocab_size, vocab_size)
self.position_embedding_table = nn.Embedding(vocab_size, vocab_size)
self.blocks = nn.Sequential(*[Block(n_embd, n_head=n_head) for _ in range(n_layer)])
self.ln_f = nn.LayerNorm(n_embd)
self.lm_head = nn.linear(n_embd, vocab_size)
self.apply(self._init_weight)
def _init_weight(self, module):
if isinstance(module, nn.Linear):
torch.nn.init.normal_(module.weight, mean =0.0, std=0.02)
if module.bias is not None:
torch.nn.init.zeros_(module.bias)
elif isinstance(module, nn.Enbedding):
torch.nn.init.normal_(module.weight, mean =0.0, std=0.02)
def forward(self, idx, targets=None):
# 取出token编码和对应的位置编码
tok_emb = self.token_embedding_table(idx) # (B,T,C)
pos_emb = self.position_embedding_table(torch.arange(T, device=device)) # (T,C)
x = tok_emb + pos_emb
x = self.blocks(x)
x = self.ln_f(x)
logits = self.lm_head(x)
if targets is None:
loss = None
else:
B, T, C = logits.shape
logits = logits.view(B*T, C)
targets = targets.view(B*T)
loss = F.cross_entropy(logits, targets)
return logits, loss
def generate(self, idx, max_new_tokens):
# idx is (B, T) array of indices in the current context
for _ in range(max_new_tokens):
# crop idx to the last block_size tokens
idx_cond = idx[:, -block_size:]
# get the predictions
logits, loss = self(idx_cond) # 会自动调用forward
# focus only on the last time step
logits = logits[:, -1, :] # becomes (B, C)
# apply softmax to get probabilities
probs = F.softmax(logits, dim=-1) # (B, C)
# sample from the distribution
idx_next = torch.multinomial(probs, num_samples=1) # (B, 1)
# append sampled index to the running sequence
idx = torch.cat((idx, idx_next), dim=1) # (B, T+1)
return idx