
在我们的学习过程中,会学习很多用来做黑盒优化问题的算法,虽然这些算法各不相同,但是,当我们深入它们背后的本质,就可以发现一条贯穿所有算法的线索,根据这条线索,我们可以快速地理解和掌握所有算法。这条线索就是“探索和利用”。
以下是我接触过的黑盒优化算法,从简单的模拟退火到用于大模型训练的强化学习,它们都有一样的本质。我相信也还有很多算法遵循着这样的“探索和利用”哲学。
总述
黑盒优化算法,就是我们有一个函数空间,我们不知道这个空间的具体表达式,所谓“黑盒”;但是,我们要在这个空间中找到一个最优的x,使得这个x对应的y最优。
比如,在数据库knob tuning的场景中,就是找到一组最优的knob配置(x),使得DBMS的延迟最低或者吞吐量最高(y)。
黑盒优化算法根本上要做的,并不是求函数空间的表达式,而是求一个可以让人满意的x(有时候这个x可能只是一个局部最优解,但是它已经足够满足用户的需求,这时候,我们也可以停止算法了。)这一点很重要。
所以对一个优化算法来说,最重要的就是“快速地探索,找到最优的x”。那么这个过程中,算法本质上考虑的是:如何高效地选择下一个点。
想象一下,如果我们有足够的资源和时间,我们可以穷举出函数空间中的所有点,从而得到函数空间的模样,然后找到那个最优点。但是太昂贵了,现实场景中,由x计算y值可能需要很多的耗时。所以,“如何高效地选择下一个点”,以便最快地找到那个让人满意的x点,确实很重要。
模拟退火
算法本质:如果新状态的解更优则修改答案,否则以一定概率接受新状态。这里就体现了探索和利用的思想。
算法过程
首先以一个随机点random_x开始, random_x = now_x,计算f(random_x)。假设我们要求最小值。
之后我们随机移动到下一个点,比如可以这样:
new_x = random_x + random.uniform(-1, 1)再计算f(new_x),如果new_x更优,也就是f(new_x)更小,我们更新now_x = new_x;
否则,我们以一定的概率接受这个new_x,这个概率是像下面这样指定的(图源模拟退火 - OI Wiki):
 我们写一个while循环进行上面的过程,在每一轮循环中,更新温度
我们写一个while循环进行上面的过程,在每一轮循环中,更新温度T,一般的做法是乘以一定的百分数使得T衰减,从而达到退火的作用;然后设置终止条件,这样整个算法就完成了,还是非常简单的。
如何“探索-利用”
很明显,在模拟退火算法中,“以一定概率接受新状态,尽管新状态不比现在的解更优”,就是一个"探索"的过程。这个核心思想有助于算法跳出局部最优解。
随着算法的进行,温度T不断衰减,于是接受新状态的概率也越来越小了。因为随着时间推进,对函数空间的认识增加,所以更偏向“利用”,而不是“探索”了。
遗传算法
我们可以认为,参数“精英选择概率”,就是进化算法中一个平衡“探索和利用”的工具。
我们可以看到,模拟退火选择下一个点的策略还是比较简单的,它以一定的概率接受下一个随机点,尽管这个点的y值可能不那么好。
遗传算法是如何 “高效地选择下一个点进行探索” 的呢?
表面上遗传算法不是选择点的算法,毕竟它使用一个“种群”,并使得“种群”不断进化。但是本质上,“种群”就是最优点可能出现的“离散区间”,这个离散区间是由一个个非常promising的个体(x)组成的,通过交叉和变异——本质上是对x的值进行扰动,并且在用“扰动”产生新种群(区间)的过程中,算法还考虑到了原本种群个体之间的联系。
那么我可以在这里先总结下:遗传算法(或者任何基于遗传算法的进化算法),本质就是要产生新的离散区间,使得区间里包含最优解的概率越来越大。
算法过程
首先定义超参数:种群大小p,迭代次数num,变异概率mutate,交叉概率c,精英选择概率e。假设我们要求最小值。
首先在x的取值空间中,随机生成p个个体,x1,x2,...,xp ,作为初始种群。之后对于每个个体,根据变异概率和交叉概率决定是否产生新个体。具体的实现根据不同的进化算法有所不同,这里用最简单的遗传算法举例:
对于
xi,假设它是一个含有m个维度的向量,我们的变异策略可以设置为:随机选择m个维度中的一个维度,如果取的随机数小于变异概率,那么就改变这个维度的值;交叉策略可以设置为:随机选择一个之前未和该个体交叉过的个体
xj,二者交换从位置n(1<n<m)开始的向量切片。我们把通过变异和交叉产生的新个体,包括原来的种群一起,放入
pop_forselect,从中选择p个个体,作为新的种群 ,然后进入下一轮循环。
如何“探索-利用”
刚刚说到,“放入pop_forselect ,从中选择p个个体”,这里实际上就是产生新的离散探索区间的过程,如何选择,就体现了“探索和利用”。
精英选择概率e,表示我们要选择p*e 个精英个体。也就是从pop_forselect 中选出p*e 个表现最好的个体(即对应的y最小的前p*e 个x)。这体现的是利用。
剩下的 (1-e)*p个个体,随机选择。这体现的是探索。
对于目前已经表现出优秀值的个体(也就是精英),它们所在的区间是很有前景的,也就是有很大概率产生最优x,所以我们要“利用”这些区间;但是我们也不能放弃那些表现还没那么好的个体,因为它们所在的区间有可能帮助我们跳出局部最优区间,所以也要留1-e的概率进行“探索”。
贝叶斯优化
BO中,用来平衡探索和利用的是Acquisition Function。
算法过程
下面的PPT截图来自视频:
贝叶斯优化 | 黑盒优化+全局最优方法 | Bayesian Optimization_哔哩哔哩_bilibili
首先,要明白的是BO有两个关键模块,也就是代理模型(Surrogate Model)和获取函数(Acquisition Funtion),算法的过程也是围绕这两个关键模块展开的。

注:这里的代理函数,使用的GRP,是高斯过程回归,这个代理函数还可以是随机森林等,不一定要是GRP。
假设我们要求最小值。
最开始的时候,我们需要对BO进行初始化,也就是让BO对我们的函数空间有一个基本的认识,初始化的做法是进行采样,随机选取一些
x,计算对应的y,作为我们的observation。假设我们先取了k个x,x1,x2, ... ,xk之后,BO的代理模型会根据这
k个x构建对黑盒函数的理解,更加具体地说,它假设黑盒函数服从一个概率分布,这个分布的方差和均值由这这k个x求得。(看下面的PPT图片)
 根据这个分布,我们可以在函数空间里,得到每个
根据这个分布,我们可以在函数空间里,得到每个x点对应的y值的均值(表现的期望)和方差(表现的不确定性)。也就是下面右边的图体现的,阴影部分是由方差构成的上下置信界。
左图到右图的过程,体现了BO的代理模型建立起了对黑盒函数的初步理解(这个理解是基于概率估计的)。

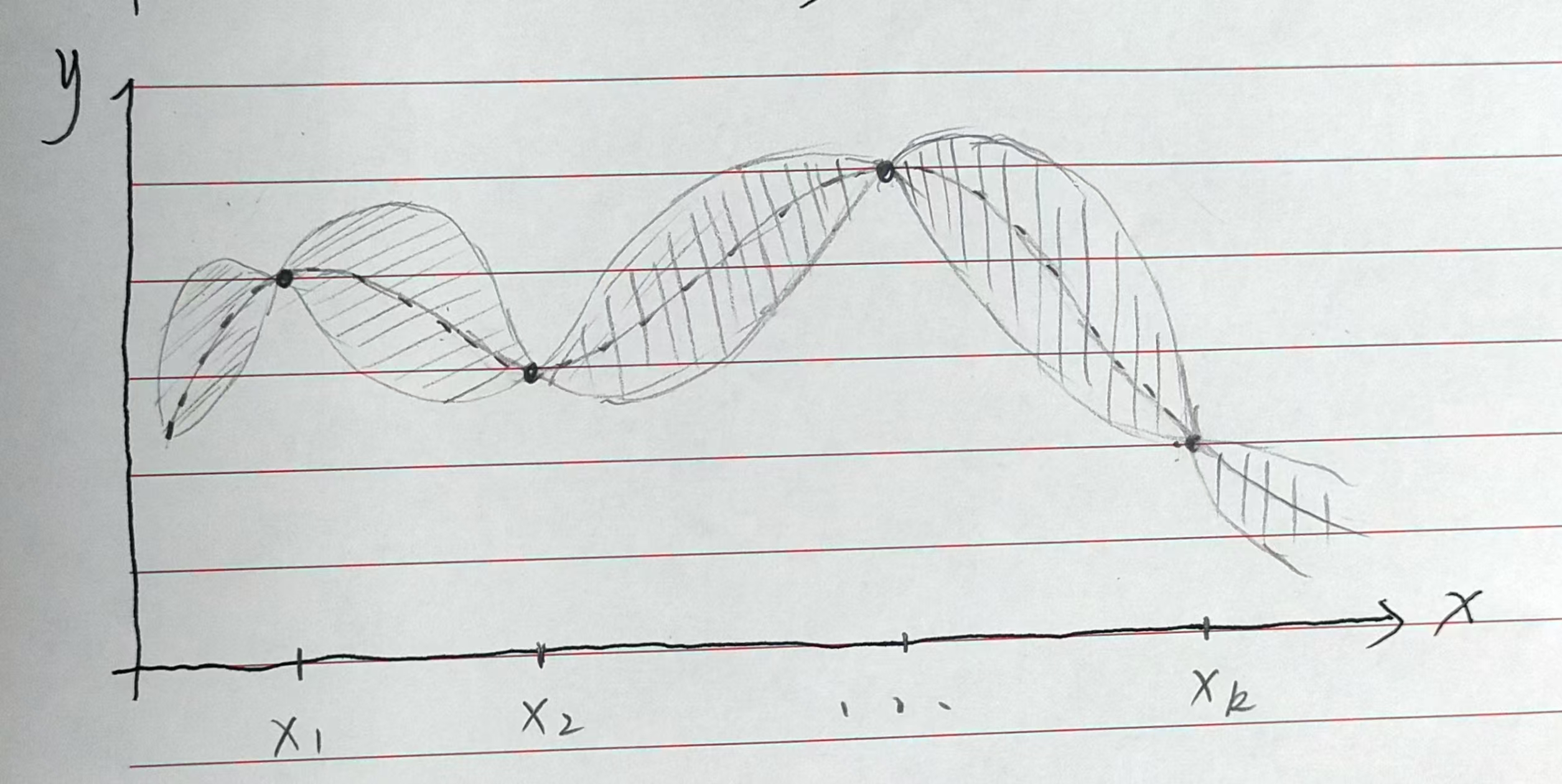
之后,BO会根据获取函数,获得下一个采样点
x和对应的y值,根据新的点,代理模型更新概率分布的均值和方差,从而更新对黑盒函数的理解。如下图所示。
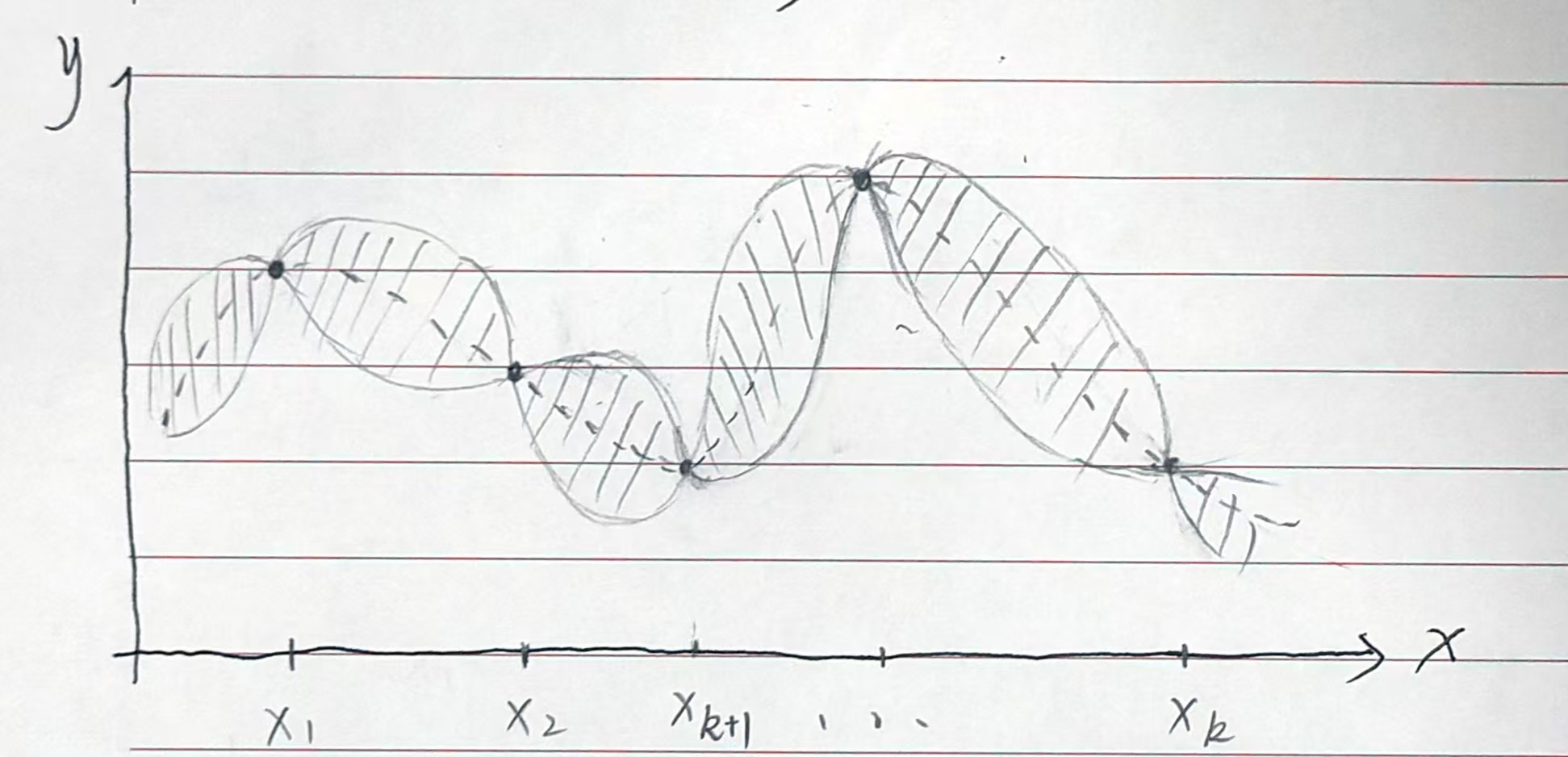
可以想象,当我们如此一轮轮进行迭代,当采样点 x 越来越多的时候,我们的代理模型对黑盒函数的理解就会更加精确。(可以认为这就是一个对代理模型进行训练的过程)
如何“探索-利用”
很明显,这里控制“如何选择下一个点”的部件是获取函数,所以就是利用它来平衡“探索-利用"的。
获取函数有很多种,常用的有Upper Confidence Bound (UCB),Probability of Improvement (PI),Expected Improvement (EI)。下面可以简单介绍一下这这几个函数。
博客Acquisition functions in Bayesian Optimization | Let’s talk about science!
对我理解获取函数的作用帮助很大。
(写到这肚子有点饿,暂停一会呃)
获取函数使用的均值和方差,都是从代理模型那里获得的;
从下面的内容可以发现,BO在获取函数这里,也需要调整超参数。
UCB
这个获取函数特别简单,它对各个点函数值的估计是这样的:
f(x;λ) = μ(x) + λσ(x)
这里的参数λ是控制这种权衡的关键参数。
当
λ较小时,获取函数会倾向于选择那些预期性能较高的解决方案,即那些具有较高μ(x)的解决方案。也就是说,当λ较小,获取函数会更加关注那些已知可能带来高回报的点。相反,当
λ较大时,获取函数会鼓励探索当前还未被探索的搜索空间区域。这意味着算法会倾向于选择那些不确定性较高的区域,即那些σ(x)较大的区域。当λ较大时,获取函数会更加重视探索新的、未知的点,以期望发现更好的解决方案。
PI
PI,也就是改进概率。这个指标的构建是基于UCB的。
首先,我们构造一个指标I(x),表示一个新的探索点x相比目前已有最佳点x*的提升。
I(x)=min(f(x)−f(x*), 0)
我们的例子求最小值,用min, 否则就是用max。
让我们假设上面UCB中的参数λ 也服从正态分布,即λ∼N(0,1) 那么,f(x;λ) = μ(x) + λσ(x) 就是一个期望μ(x),方差σ2(x)的正态分布。
把f(x;λ) 带入I(x) 可得:
I(x)=min(f(x)−f(x*),0)=min(μ(x)+σ(x)z−f(x*), 0) z∼N(0,1)
那么,我们要算一个点的改进概率,也就是该点比我们目前有的最佳点更优的概率,就是:
Pr(I(x)< 0) = Pr(f(x)<f(x*)) ⇔ PI(x)
接下来可以借用博客里面的一张图,博客用的例子是求最大值,我们求最小值的话,就是紫色区域为改进概率: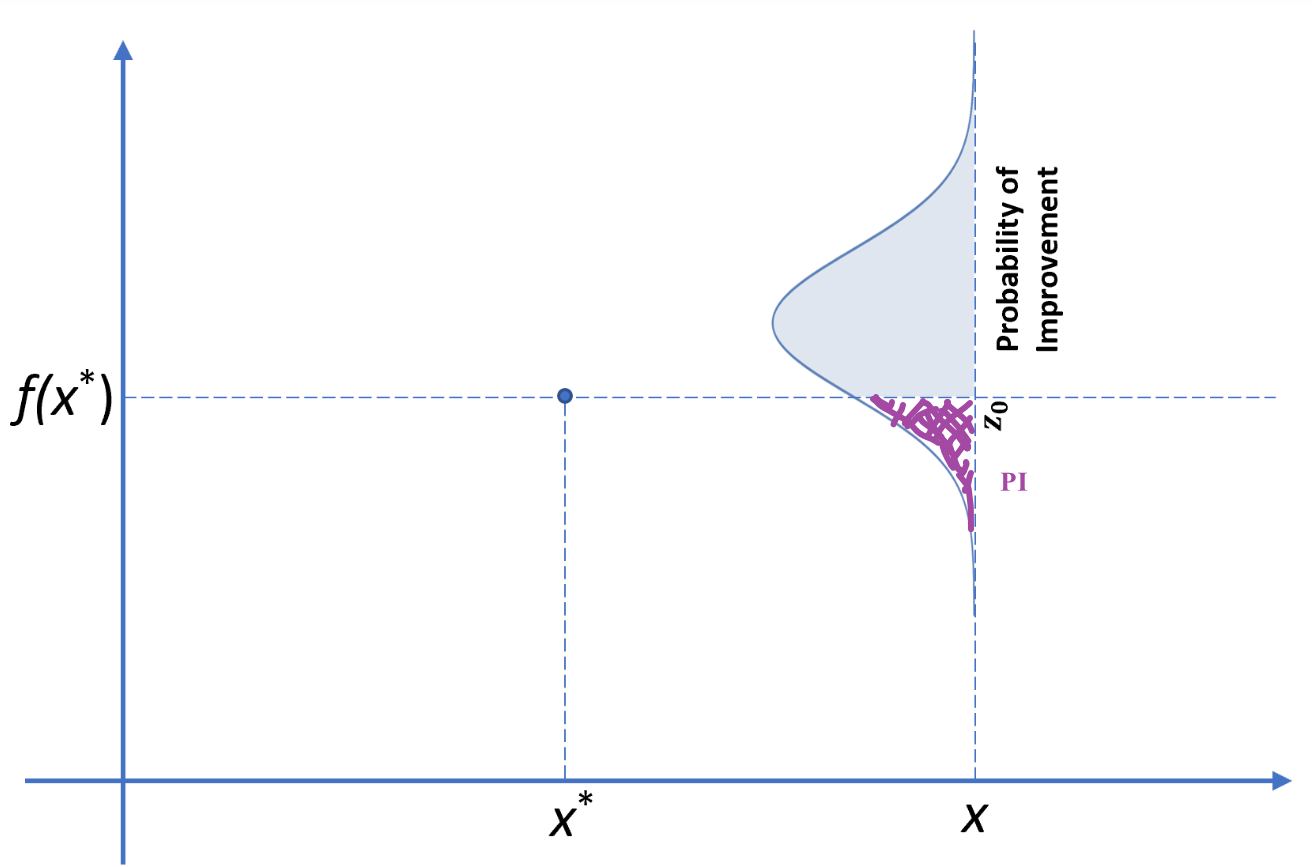
PI(x)=Φ(z0)
EI
刚才的PI其实只考虑了改进概率,没有考虑改进幅度。
EI其实也很简单,就是我们刚刚构建了一个指标I(x) ,那么EI就是I(x) 在其概率密度函数上面的积分啦。
一张博客里的图看EI表达式怎么推导的: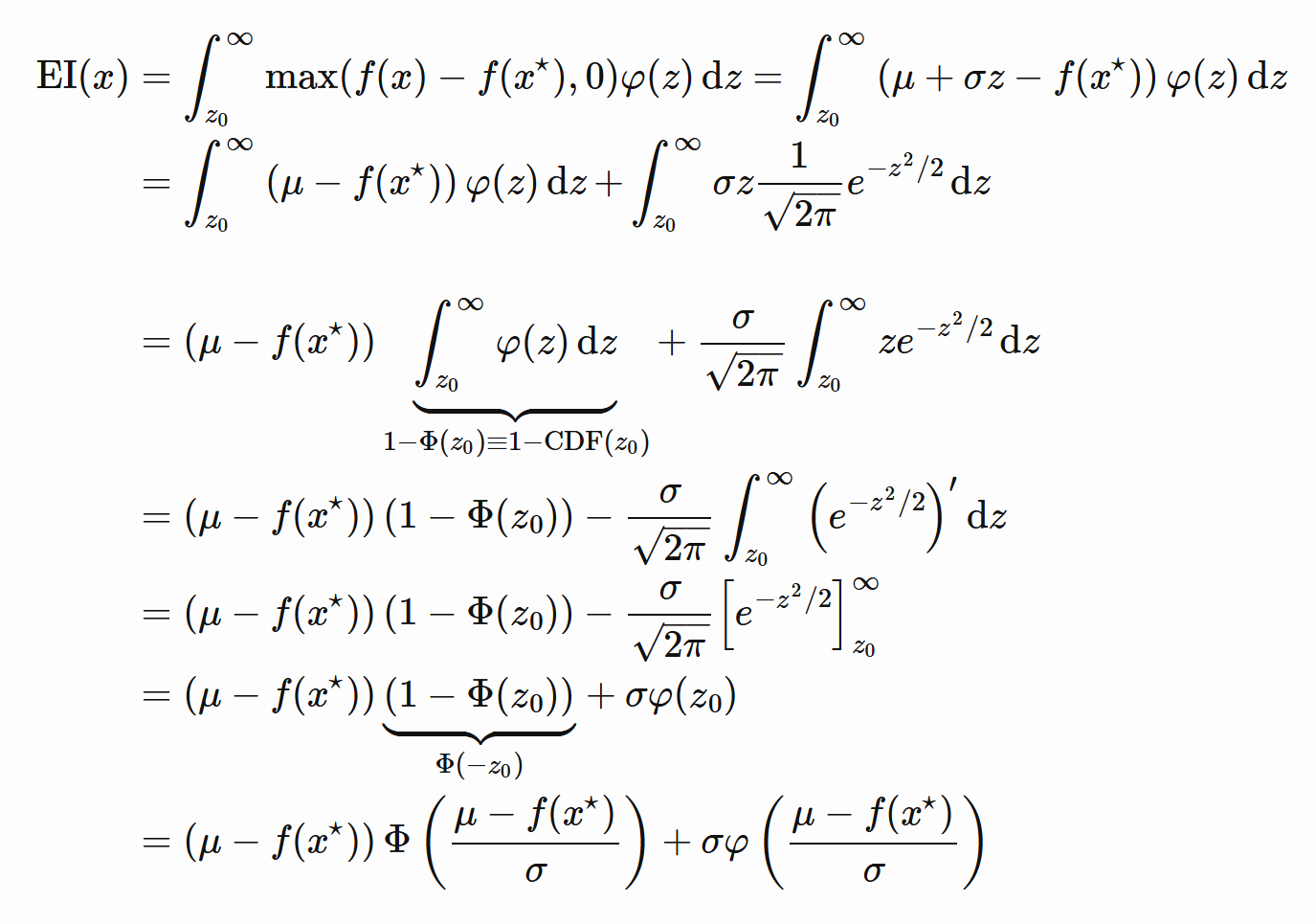
最后,我们会为EI 增加一个超参数ξ ,用于调整我们“探索-利用”的幅度。
 可以这样理解:我们原本已有的最佳值是
可以这样理解:我们原本已有的最佳值是f(x*) ,但是我们现在又把这个中心点偏移了ξ ,就是假设说:我们的最优值还有可能在下一个地方,这里就是在鼓励“探索”。
强化学习
从普通的Q-Learning到Deep RL, “探索和利用” 的地位在RL中显得更加重要。
RL的内容太多了,我主要简单介绍从Q-Learning到DQN,再到DDQN和DDPG几个算法。看一下RL领域的算法是如何一步步改进的,以及这其中“探索和利用”大致是如何实现的。
关于对RL和其中“探索-利用”策略的系统总结,可以看https://pub.tik.ee.ethz.ch/students/2018-FS/BA-2018-15.pdf
Q-Learning
概览
这是最最简单的RL算法模型了。
Q-learning就是我们有一个智能体,这个智能体通过和环境的交互,也就是在所有状态下,执行所有可能的动作;在这个过程中,它不断更新在某状态下做出某个动作会得到的回报值。这其实是一个填表的过程:
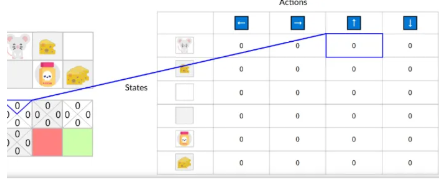 (图源:https://huggingface.co/learn/deep-rl-course/en/unit0/introduction#certification-process)
(图源:https://huggingface.co/learn/deep-rl-course/en/unit0/introduction#certification-process)
最开始的时候,表格里面的值都是零,也就是智能体对迷宫浑然不知。随着不断的探索,它得到了越来越多的经验,表格里的值就会逐渐更新,并且越来越准确。我们把这些叫做Q值。
如何更新
贝尔曼方程(Bellman equation)在Q-learning中被用来更新Q-值,或者说动作价值函数(action-value function)。这个更新过程是基于当前动作所获得的奖励以及下一个动作的预期回报来进行的。
动作价值函数,通常表示为Q(s, a),是指在状态s下采取动作a所期望获得的累积回报。贝尔曼方程提供了一种方法来计算这个期望回报,它考虑了当前动作的即时奖励以及下一个状态的预期回报。
1. 当前奖励:这是当前动作直接获得的奖励。
2. 下一个动作的预期回报:这是基于当前策略,下一个状态可能采取的最优动作的预期回报。
贝尔曼方程长这样:
 (图源:Q-learning - A Quick Introduction (with Code) | Dilith Jayakody)
(图源:Q-learning - A Quick Introduction (with Code) | Dilith Jayakody)
在实际算法中使用的时候,贝尔曼方程会和其它一些参数一起来更新Q值,比如下面这样:
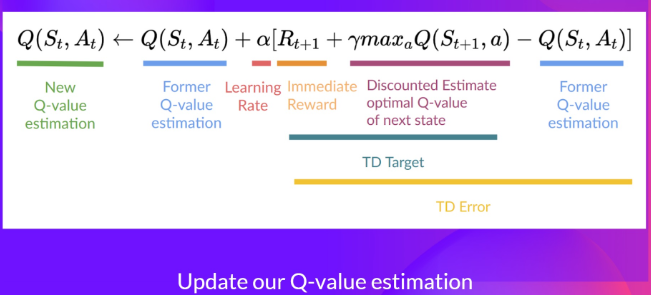 (图源:The Bellman Equation: simplify our value estimation)
(图源:The Bellman Equation: simplify our value estimation)
如何“探索-利用”
同样的,在Q-learning的过程中,智能体也要考虑”如何高效地选择下一个点“或者说”怎么走下一步“的问题。
Q-learning采用比较简单的ε-greedy策略。
ε-greedy策略具体如下:
ε(epsilon):这是一个小概率值,用于控制智能体选择随机动作的频率。当智能体采取ε-greedy策略时,它将以ε的概率选择一个随机动作。
1-ε:这是智能体选择具有最高期望回报的动作的概率。因此,大部分时间(1-ε的概率),智能体会选择那个根据当前知识()预期能带来最高回报的动作。
ε的值是在训练过程中不断减小的(有点像退火算法里面的温度)。最开始这个值比较高,因为需要频繁探索以便快速学习,之后逐渐降低,因为智能体对我们的函数空间愈加了解了,探索的空间减少,利用的机会更多了。像下面这样: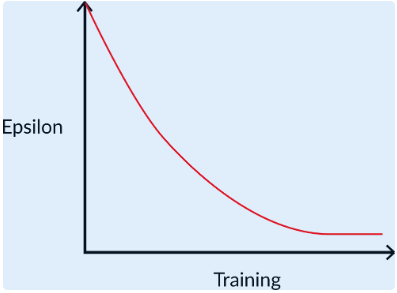
DQN
概览
Q-learning是填表,但是,要是状态特别多(现实生活一般是这样的)要开那么大的表,就问要多大内存吧。
所以就有了DQN。输入是状态,输出是对当前状态下,各种可能动作对应奖励值的估计。
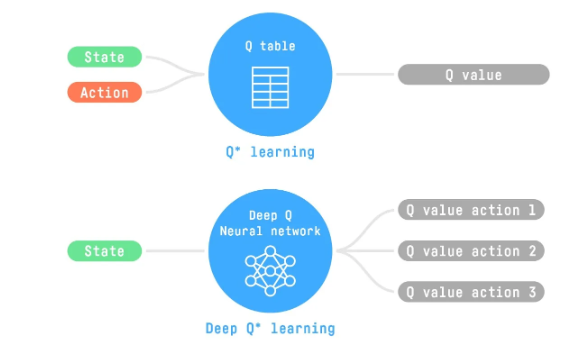 如何更新
如何更新
 在Q-Learning中,Q-Table存储了智能体对函数空间的理解,而这里,就是神经网络参数存储了对函数空间的理解。更新神经网络参数,也就是智能体学习的过程如下:
在Q-Learning中,Q-Table存储了智能体对函数空间的理解,而这里,就是神经网络参数存储了对函数空间的理解。更新神经网络参数,也就是智能体学习的过程如下:
首先由输入的状态,输出对当前状态下,各种可能动作对应奖励值的估计。这个估计值是Q-value prediction
从中选出奖励值最大的动作执行,执行之后得到Q-target,使用贝尔曼方程得到的。
之后求Loss,再用Loss和梯度下降更新参数:Loss计算如下

如何“探索-利用”
DQN和很多DRL一样,它们平衡“探索-利用”有两个重要的方面:
经验回放Experience Replay:
在线的强化学习算法会面临下面一些问题
在线学习一个样本点,用这个样本点更新网络参数后,这个样本点就被抛弃了。
过去的经验会被遗忘,尤其是智能体处于分级的,有很多子模式的环境中时。举例来说,如果一个智能体首先处于第一级,然后转移到第二级,而第二级与第一级不同,那么智能体可能会忘记在第一级时的行为和玩法。因为如果两个级别之间的差异很大,智能体可能需要重新学习或适应新级别的行为模式,以至于它可能忘记了在旧级别中的行为模式。这类似于人们在不同情境下可能需要采取不同的行为方式,而在新情境中的行为可能会影响或取代旧情境下的行为习惯。
智能体在环境中的交互是按时间顺序连续进行的。这意味着连续的经验之间可能存在高度的相关性,因为它们是智能体在相似或连续状态下的连续决策结果。而高相关性的样本可能导致模型学习到训练数据中的特定细节,而不是底层的分布规律,降低模型的泛化能力。
于是,就设置了一个Replay Buffer,存储经验元组。每次更新神经网络的时候,除了使用在线得到的样本,还会从Buffer里面随机取一些样本,这两部分样本一起训练模型。
经验回放体现的是“利用”的哲学,通过“走走之前走过的点”,使得模型的训练更加稳定和有效。
探索是门大学问:
RL中,如何鼓励智能体多多去探索,是一个很重要也很有趣的问题,还可能借助一些心理上的理论,详细的研究可以见:
Exploration Strategies in Deep Reinforcement Learning | Lil'Log
这里我就介绍一个简单的鼓励探索的方法,它是用在Loss函数上的,叫熵损失项(Entropy loss term)。参考:Entropy loss for reinforcement learning - Chris Foster
这种方法的核心思想是通过增加一个基于预测动作熵的损失参数来鼓励代理探索更多的策略集合。
熵是信息论中的一个概念,用来衡量概率分布的不确定性或者随机性。在强化学习中,熵损失项的计算公式为:
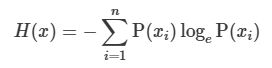 其中,P(xi) 是第 i 个动作的概率。
其中,P(xi) 是第 i 个动作的概率。
通过添加熵损失项,我们实际上是在鼓励模型不要对任何单一动作过于自信。
如果模型的预测非常集中,即某个动作的概率接近1,而其他动作的概率接近0,那么这个分布的熵就会很低,熵损失项就会很大,从而使得整体损失增加。相反,如果模型的预测分布更加均匀,即对各个动作的概率预测都比较接近,那么熵就会更高,熵损失项就会更小。
因此,在训练过程中,模型会倾向于产生更高熵的预测分布,这意味着它会探索更多的动作,而不是只选择一个或几个动作。这样的机制有助于代理避免陷入局部最优解,并且能够更全面地探索状态空间,从而有可能找到更优的策略。
其它
DDQN是基于DQN改进的,把一个网络变成两个网络;
DDPG等基于策略的算法可以弥补DQN类方法的不足,可以解决连续动作问题。
具体的下次再说吧🥺
To be continue:🛴
Highest-Level Abstraction
人生的进程,何尝不是一个探索和利用的过程呢?
如果一个人作出人生下一步决策的过程,是随机进行的,ta不管迈出下一步需要多大的成本,多远的距离。ta秉着“碰运气试试”的原则,如果这个决策看起来不比当前的生活方式更好,ta也会尝试去做,那么ta就是一个 “模拟退火人”。这种人生决策模式的缺点在于,尽管会越来越好,但是过于低效,因为ta不会仔细去想下一步该迈多大的步子,决策过于随机。
人生和这些算法类似,都面临着“探索和利用”,面临着,是利用当下已有的资源继续发展,还是走出舒适区,探索新的发展机遇。
“遗传算法人” 会同时尝试多个事情,在广泛的尝试中找到人生的最优区间。缺点就是需要耗费大量的时间和精力。
“贝叶斯人”选择利用过去的经验来构建对人生和时代的理解,通过估量下一步的收益和风险,来进行决策。
但是很多时候,人生的收益和风险是难以量化的,于是有些人会选择“强化学习”式的人生。
参考资料 Reference
https://lilianweng.github.io/posts/2020-06-07-exploration-drl/
Acquisition functions in Bayesian Optimization | Let’s talk about science!
Deep Q-Networks (DQN) - A Quick Introduction (with Code) | Dilith Jayakody