
故事的开头
前言

这是cuhk seem的笔试题,看着很简单。O(1),所以首先考虑到的是使用哈希。
但是提笔要写的时候又陷入了犹豫,脑海中未经梳理的知识忽然开始变得杂乱。(雾)
试图写下记忆中更贴近实践的那种实现(也就是接下来的第三种实现),但是失败了,写得并不那么清楚。更巧的是,面试时还被老师问到了,顿时神情紧张头脑空白。(亡)
说明虽然unordered_set和unordered_map会用,但是这部分知识还是有点遗忘和混乱了。
那么就借这个机会来重新梳理一下吧。
PS:梳理了三种实现思路,从理论上常见的两种实现到DBMS中哈希索引的实现,以及记录我在梳理过程中,一些有趣的新发现,比如标记删除,vacuum,sql重写等。
总述
首先我们回顾下哈希的精髓思想:
在顺序存储结构里,我们想要在集合里找到某个元素,想要挨个比较。理想的搜索方法是:可以不经过任何比较,一次直接从表中得到要搜索的元素。
如果构造一种存储结构,通过某种函数使元素的 存储位置 与它的 关键码 之间能够建立一一 映射 的关系,那么在查找时通过该函数可以很快找到该元素。
从high-level来说,我们设计哈希需要两个部分:一是哈希函数,用来把集合中元素的值映射到存储位置;二是存放元素的结构(数组or链表)。
不同的元素可能被映射到不同的位置,也就是发生哈希冲突;基于处理哈希冲突不同的思路,就有了下列前两种常见的设计思路。但是在实际应用中,比如dbms中,我们还需要另一个中间结构来存储哈希值和元素位置的映射(就像书本需要一个目录页来存放页码和章节大标题之间的映射一样),于是有了第三种实现思路。
闭散列实现
处理哈希冲突的第一种方式:
当发生哈希冲突时,如果在哈希表中还有空位置,那么可以把key存放到冲突位置中的“下一个” 空位置中去。
例如冲突的位置,放了小李,那么就向下找一个空位放置小王的信息。
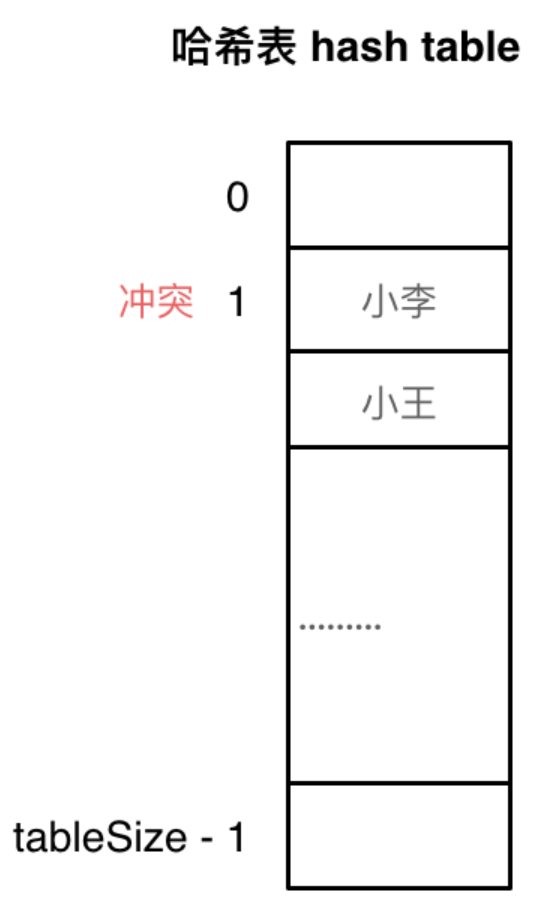
Insert
对于一个待插入的元素,首先计算它的哈希值,也就是在数组中的位置。如果位置为空就放入;
如果不为空,也就是发生了哈希冲突,这时候就要找“下一个空的位置”。找到空位置一般有下面两种方法:
线性探测:从发生冲突的位置开始,依次向后探测,直到寻找到下一个空位置为止。
二次探测法:找下一个空位置的方法为Hi=(Ho+i^2) % m,或者:Hi=(Ho-i^2) % m。其中:i= 1,2,3...,Ho是通过散列函数Hash(x)对元素的关键码 key 进行计算得到的位置,m是表的大小。
由于线性探测法是往后挨个依次找,容易发生元素扎堆,空间利用率不高+找空位很耗时的问题,比如下面图所示:
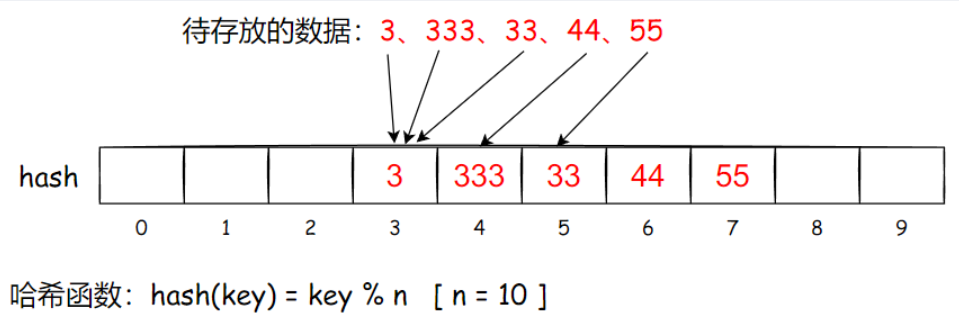
二次探测法可以比较好地解决这个问题;也有助于在查找元素时,只找几个特定的位置,不用挨个比对后面全部位置。
Delete
删除操作就会复杂点。
以上图为例,如果想要删除333,是否可以直接删除呢?如果直接删除,之后我们想要查看44是否在列表里,查到44的哈希值对应的位置为空,这时候我们无法判断:44究竟是不在列表里,还是说发生冲突后放在了后面其它位置呢?
这里采取的办法是使用标记删除。为每个存储位置增设一个标记位,(EMPTY, EXIST, DELETED)。如果删除333,我们把这里置为DELETED;之后查找44时候就会知道,这里存的是333,但是被删除了,应该往后查找下标为Hi=(Ho+i^2) % m,(i=1,2,3..)的位置,看44是否在这些位置里。
GetRandom
这里还是比较简单,生成一个随机数(但是注意一定是在数据下标范围内生成,不要越界了),用它作为索引来访问随即元素。
开散列实现
处理哈希冲突的第二种方式:
也就是把哈希值相同的元素都防在一个集合里,这个集合用链表连起来。
这里就需要数组+链表组合实现了。
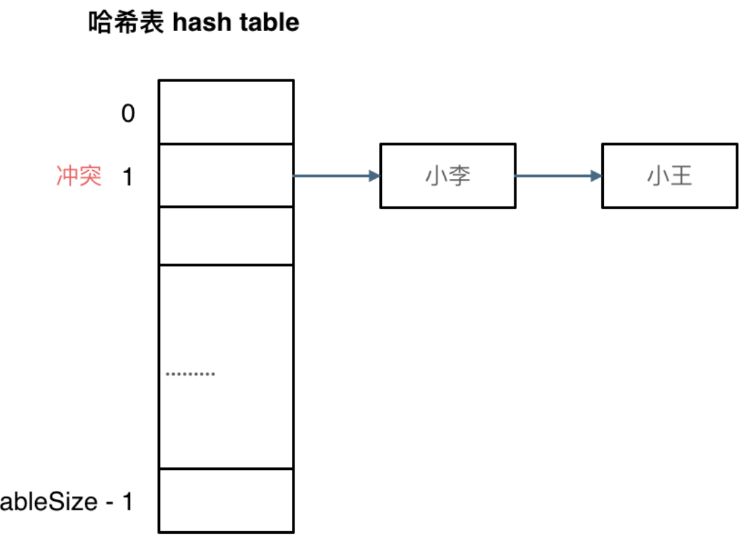
Insert
对于一个待插入的元素,首先计算它的哈希值,也就是在数组中的位置。如果位置为空就建立链表头节点,放入;如果不为空,就是在链表末尾插入新节点的操作。
Delete
计算待删除元素的哈希值,然后在链表中查找这个元素。之后就是在链表中删除某个节点的操作,编程上特别注意修改指针指向的顺序就行。
GetRandom
为了保证随机选择的公平,有两个步骤:一是随机选择一个集合(也就是数据下标);二是随机选择集合中一个元素。
# 在数组下标范围内选择一个随机数访问一个随即集合
idx1 = random(0, table_size)
# 在链表长度范围内选择一个随机数访问一个随机元素
idx2 = random(0, list_size) 如果这样的话,就要求我们在数组每个位置,除了头指针外增加维护一个元素,就是链表长度。在增删的时候记得更新即可。
(雾,发现这刚好是面试的时候答不好的问题)
如果要更加严谨一点的话,发现O(1)不是稳定的,当有很多元素哈希值相同导致链表过长,又陷入了挨个搜索,时间复杂度会退化为O(N)。
所以就有给哈希表扩容的说法,简单来说就是再开辟一块空间,然后重新按照哈希函数放置每个元素。
听着也有点麻烦,所以就有扩容优化的说法。这里就不详细记录了。
数据库哈希实现
值得一提的是,数据库中的索引有多种类型,但是很多dbms使用的默认索引是B-tree。
# 会默认创建B-tree索引
CREATE INDEX name ON table USING HASH (column);
# 创建哈希索引要特别指定
CREATE INDEX name ON table;之前没有想过的是为啥默认为B-tree。毕竟tree的复杂度为O(logN);而hash的复杂度一般是O(1)。
这里简单解释下,是因为:
在某些情况下,哈希索引可能不是最佳选择,因为它是无序的:
哈希索引在查找方面比树索引更快(对于使用
=或<=>运算符的相等比较),但它们不能用于有效地查询数据范围。查找时树索引比哈希索引慢,但它们可以用来有效查询数据范围。
而且哈希索引需要使用大量内存。
但是,在有些情况下,比如下面这样的查询,使用哈希索引效率就会很高:
SELECT Iname FROM testhash WHERE fname='Peter';假设我们有这么一个表:
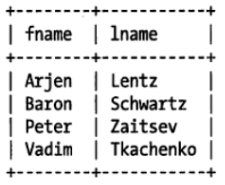
假设我们有哈希函数func( ):
f('Arjen')=2323
f('Baron')=7437
f('Peter')=8784
f('Vadim')=2458
(其实这里做了省略,应该是先计算出哈希值,再根据哈希值计算出slot值)
那么在fname列上建立哈希索引之后我们会得到下面的hash-table:
Insert
如果要插入新的一个条目,{fanme='Sophy',lanme='Lean'}。
首先根据fanme计算哈希值,然后得到slot编号,如果slot对应位置为空,就向这个位置增放一个元素,这个元素是一个指针,指向存放新条目的文件空间。然后在数据文件中写入这个条目。
如果slot对应位置不为空,也就是发生了哈希冲突(这里叫slot冲突可能更加恰当),这时候处理方式和开散列一样。如下图红框部分(不过这里把条目内容直接标上来了,实际应该是指向这些条目内容的指针+哈希值):
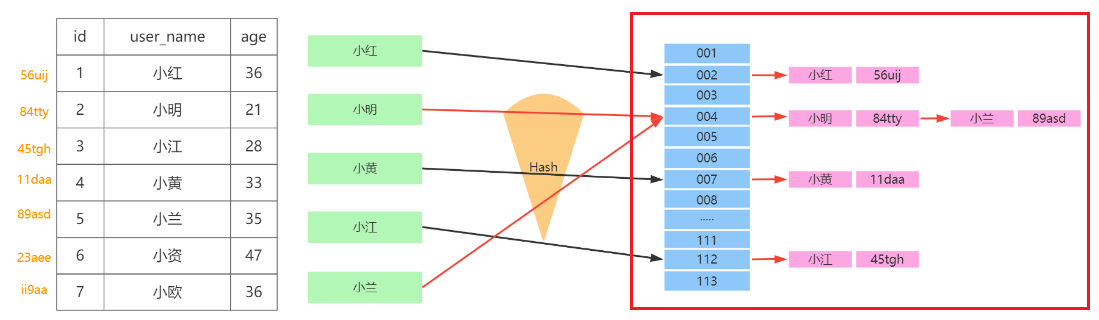
然后再在指针指向的文件空间中写入这个条目即可。
Delete
实现
逻辑上的思路似乎很简单:计算哈希值h和slot值s,查找哈希表看有无这个slot值,找到的话,去slot值对应的链表里寻找是否有哈希值为h的指针。找到的话就把这个指针回收,改变前后指针的指向。
但实际上,有趣的是,很多DBMS的设计不是这样的。以postgresl为例:
因着数据库的 MVCC 多版本并发控制的概念,PostgreSQL 在删除/更新记录时是这样处理的:
删除:对数据记录进行标记删除,不会在物理存储中真实的删除它。
更新:对数据记录进行标记删除,并且插入新的记录。
比如:
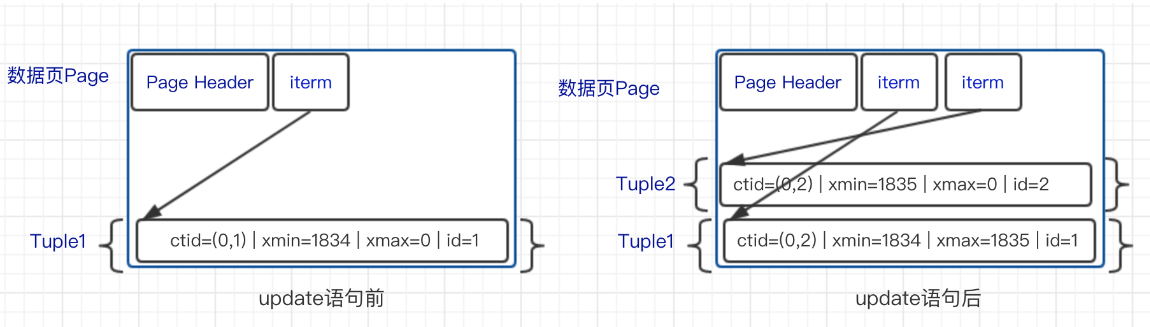
也就是说,update Tuple1的方式是把它的xmax,由0更改为update它的事务ID号,然后再增加一个新的条目。
而delete的方式也是类似的,条目数量不会增加但是也不会减少,如果ID为1836的事务操作要删除Tuple1,只要把Tuple1的xmax修改为1836。
为什么要这样做呢?简单来说是为了协调事务之间的关系,服务不同的事务。因为事务A想要删除一个条目的时候,另一个事务可能正在读这个条目;用这个思路处理,可以避免加锁之类的操作,提高效率。更加具体的就要去了解下MVCC了。 通俗易懂数据库MVCC讲解,后悔没早点学-腾讯云开发者社区-腾讯云 (tencent.com)
Vacuum
这时候又有一个问题,那就是,如果不删除的话,我们的无用Tuple会越来越多,很浪费页面空间。(毕竟事务并发结束之后,我们的数据就彻底更新,老的数据就不用了,删除老数据对事务没有不良影响)。
于是就查到了这个,之前没咋关注过的vacuum操作:
VACUUM回收死行占据的存储空间。
在一般的PostgreSQL 操作里,那些已经 DELETE 的行或者被 UPDATE 过后过时的行并没有从它们所属的表中物理删除; 在完成VACUUM之前它们仍然存在。因此有必要周期地运行VACUUM, 特别是在经常更新的表上。
插播:想起来knob-tuning里面有很多”vacuum“家族的knob,但是未关注过具体用法,这里就举例介绍下,刚好了解下vacuum是怎么工作的。
log_autovacuum_min_duration = 1(超过1秒的vacuum操作将被记录)
autovacuum_max_workers = 3 autovacuum_naptime = 1min
autovacuum_vacuum_threshold = 50
autovacuum_analyze_threshold = 50
autovacuum_vacuum_scale_factor = 0.2 autovacuum_analyze_scale_factor = 0.1
autovacuum_vacuum_threshold = 50
autovacuum_vacuum_scale_factor = 0.2
公式为 50 + 总行数的20% = 触发autovacuum
假设你的表为 1000行,则表中的行如果update delete 的数量超过
50 + 1000*0.2 = 250 行, autovacuum 就开始工作了。
但如果你的表是 1000万行,那么工作的数量就变为
50 + 1000万*0.2 = 200万零50行 才能触发autovacuum
所以表越大,dead tuple 也会泛滥,数据库的性能就越低,想要调整平衡这两个参数。 这也是体现knob-tuning重要性的一个场景了。
GetRandom
哈希实现
也就是随机选取一行。这里我觉得实现思路和开散列的GetRandom是一样的,小区别在于,”idx2“对应的是一个随机指针,还要用这个指针去文件空间里访问具体行的内容。
SQL实现
这时候自然地会想:如果使用sql从表中选取随机一行应该怎么做呢:
# 给每行按照随机值排序,选择前面一行
select * from table order by random() limit 1;这样的思路比较简单,但是当我表很大,比如有500million的数据的时候,这样做会很慢:因为我需要为每一行赋一个随机值,然后还要进行排序。
那么这就是一个具体需求场景下的sql重写问题了:
恰巧StackOverflow上有这样一个问题:
https://stackoverflow.com/questions/8674718/best-way-to-select-random-rows-postgresql
# 原sql
select * from table order by random() limit 1000;
# 改写后的sql
SELECT *
FROM (
SELECT DISTINCT 1 + trunc(random() * 5100000)::integer AS id
FROM generate_series(1, 1100) g
) r
JOIN big USING (id)
LIMIT 1000;改写后的sql使用子查询生成随机的id值,然后与目标表的id字段进行连接(如果建立索引的话,连接会很快,领先于order by),最后限制结果数量,达到随机选择的目的。
(把这个例子作为查询重写的研究case,加入我们的案例也是很有意思的,内核肯定完成不了这样的任务,但是它可以作为一条”典型案例“被知识+经验体系识别。)
参考资料
https://blog.csdn.net/2301_77509762/article/details/137358612
PosrgreSQL 学习计划——Vacuum 清理机制 (yasking.org)
Postgresql autovacuum 3 怎么调整参数,拯救你惨淡的性能-腾讯云开发者社区-腾讯云 (tencent.com)
https://stackoverflow.com/questions/8674718/best-way-to-select-random-rows-postgresql